The following is a glossary-like list that shortly touches upon various subjects that one should be aware of before setting up a new VAMDC node.
As already mentioned in the Introduction, data needs to reside in a relational database in order to use the node software for a VAMDC node. This is what we mean by database in the following, in contrast to data set which means the data in any format or data model:
The data model is a definition of the database layout in form of Python code where a class is defined for each table in the database and the members of the class are fields that correspond to the tables’ columns. The data model also defines the connections between tables. For an existing database the data model can be automatically generated, otherwise it needs to be written for a new node (see Step by step guide to a new VAMDC node later) and will then be used to create the database.
Having this code representation of the database layout has many advantages, among these are:
Note
Sometimes the singular data model refers to a single model (i.e. a table in the database) and sometimes the full set of models, describing the whole database layout.
In order to facilitate automated communication, there is a need for a set of names that identify a certain type of data. Each name is unique and is uniquely associated with a description, a data type, a unit where applicable and a (non-mandatory) restriction.
For illustration, let’s have a look at one entry of the dictionary:
| Keyword | short descr | long description | data type | restriction | unit |
|---|---|---|---|---|---|
| AtomMassNumber | Atomic mass | Atomic mass in Daltons, which is the same as the unified mass units (1Da = 1u = 1.660 538 86 (28) e-27) | (Float|Double) | >1 | amu |
It is the first column that contains the name that we use globally within VAMDC for a certain bit of information. This is what we mean in the following when we talk about “global names” or “keywords”.
The full VAMDC dictionary is still being worked on and it currently resides at http://dictionary.vamdc.eu/ where also some helper tools are provided.
At the nodes, the dictionary is used in the following different ways. Note that some keywords do not make sense being used in all three cases. Common sense applies.
Note
The Returnables and Restrictables, as described in the following, are different for each node (depending on the data it offers and its structure) and need to be written when setting up a new node.
Each node keeps a list of global names that we call the Returnables. This list contains the names associated with the kinds of information that a node has to offer. This is list is offered as XML at the tap/capabilities/ URL end point which allows user applications to decide whether it is worth to query a certain node for a certain bit of data, or not.
The node software stores the Returnables not only as a list of global names, but as a list of key-value pairs where the names are the keys and the values are the corresponding places of the data in the data model (see above). This way, the Returnables become a simple one-to-one map between the global names, used by all VAMDC nodes, and the node-specific layout of the database.
This “translation” is then used, among other things, by the code that fills the data into a certain output format which in turn can become node-independant. Thereby each Returnable corresponds to a certain place (a column in table format, or a certain XML tag) in the output format.
It is the list of global names that make sense to use as constraints for a certain node and therefore tells which names from the dictionary can be used in the WHERE-clause of a query to the node (see query language below).
Again, the node software uses the Restrictables as a list of key-value pairs where the keys are the global names and the values are the corresponding place in the data model. As for the Returnables, this one-to-one map of global names to custom data model allows to translate between the two - this time when the query is parsed at arrival. The code for parsing the query uses this and can thus be re-used by all nodes without altering the code.
Requestables are a third way of using the dictionary. They are used in the SELECT-clause of the SQL expression when one wants to recieve only a subset of the data that matches the restrictions. For example, SELECT Species, RadiativeTransitions would return only the fields in this group and skip any information about the states, if it were available.
The registry is a central web service where all VAMDC nodes are registered with their access URL and some additional information. This allows finding nodes before sending queries to them. You will need to register your node there once the setup is complete.
Note
What follows below is not necessary to know for setting up a new VAMDC node but it helps to get the broader picture.
TAP stands for Table Access Protocol and is a Virtual Observatory standard definition of a web service. The detailed specs can be found here. All VAMDC nodes offer their data though a TAP-like interface which means that the URL end-points are named like in TAP, the most important being /tap/sync for a data query which returns the data synchronously (in the immediate reply). Also the attribute names for submitting a query are strongly inspired by TAP so that a query to a single VAMDC node looks something like this:
http://domain.of.your.node/tap/sync/?LANG=VSS1&FORMAT=XSAMS&QUERY=query string
VAMDC nodes currently only use and support a subset of the TAP standard, i.e. that parts that are needed within the VAMDC. Keep in mind that users will not primarily query an individual node but use a higher level tool like the VAMDC portal for querying many nodes at once. Data providers that want to set up their own VAMDC node do not really need to care about TAP either.
The more detailed specification of the VAMDC variant of a TAP service can be found in the standards documentation at http://vamdc.org/documents/standards/.
The node software uses the VAMDC SQL-subset 2 (VSS2) which is a superset of VSS1 for query language as defined in the VAMDC standards. This is basically a SQL-like string where the database layout of the node does not need to be known - instead one uses the keywords from the dictionary in the WHERE part to restrict the selection of data. This means that all nodes understand identical queries and there is no need to adapt the query to a certain node.
Details can be found in the VAMDC-TAP specification (see link above) and should not be necessary to know for setting up a new VAMDC node. Defining the Restrictables and Returnables is enough for allowing the node software to take care of the rest.
XSAMS stands for XML Schema for Atoms, Molecules and Solids. It defines a strict way to represent data in XML. XSAMS is the format in which VAMDC nodes send their data replies.
Link to the VAMDC-XSAMS project on Sourceforge.
The NodeSoftware provides an implementation of the XSAMS schema and data providers need not know it in detail to set up a VAMDC node. However, basic knowledge of its structure is needed to be able to write the few bits of code as explained in the next chapter.
XSAMS is a hierarchical structure which simplified looks like this:
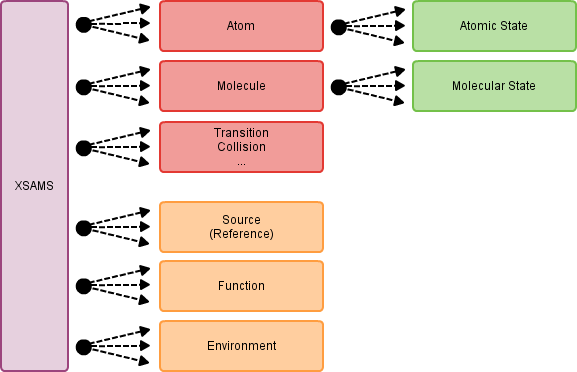
Inside each box resides all the data that corresponds to it. The atom box holds the name, atomic number, masses, iosotopes, ionization and so on. The atomic state box holds the state energy, quantum numbers and so on.
The different parts are interlinked, for example each atomic state has an ID and the transitions can refer to them as their initial and final state. Sources (i.e. publications) can be referenced, again by their ID, for each bit of information provided.
The node software comes with an implementation of the XSAMS that can (but need not necessesarily) be used by all nodes, aka the XSAMS generator. This frees data providers from the need to know about XML and the details of the schema. In order for this to work, data providers need fill the Returnables as described above and in the next chaper. The generator then knows how to put the data into the schema.
In principle, XSAMS allows many more nested loops than are shown in the diagram above. But since each node needs to build from its database the structure that matches the hierarchy, we have made some deliberate simplifications. For example we treat each ion and isotope or an atom as a different atom/species. This means that skip the complexity of having five or more nested loops at the expense of replicating some information.
The portal is the obvious example of a user application that makes use of VAMDC nodes. It is a web site that facilitates the submission of a query to many nodes at once by providing a web form out of which it assembles the query string which it then sends to one or many nodes, gathers the results from each of them and presents them to the user.